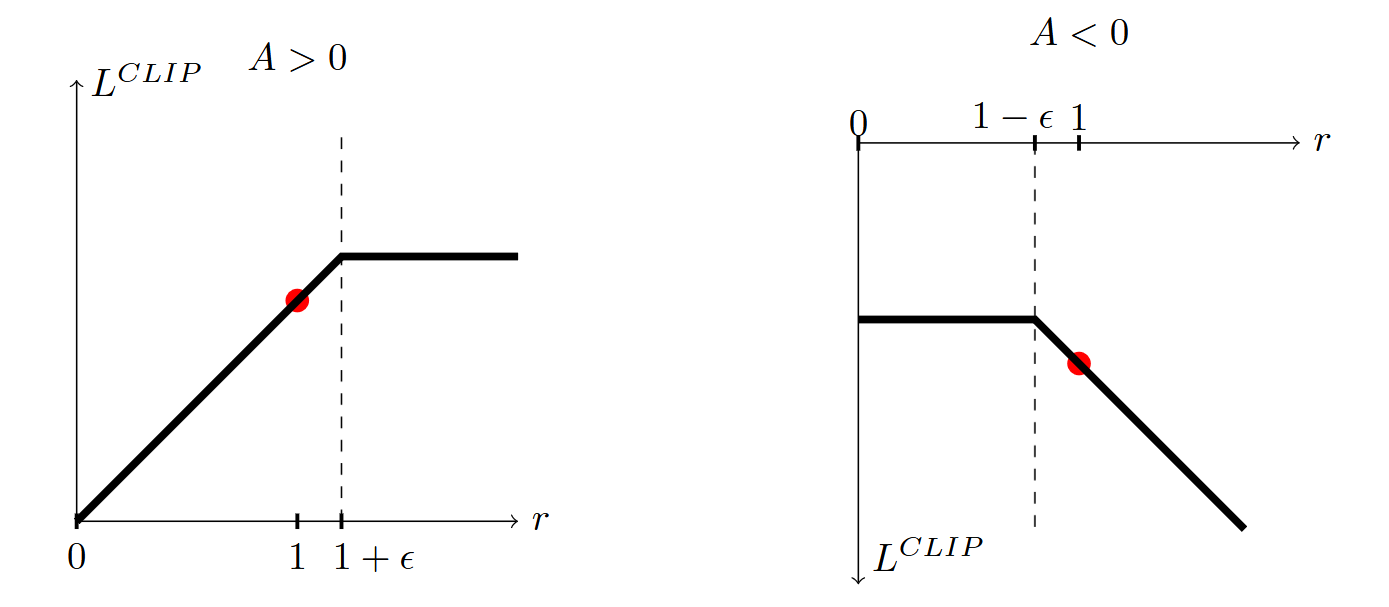近端策略优化 (Proximal Policy Optimization, PPO) 是一种基于策略梯度的强化学习算法,由 OpenAI 在 2017 年提出。
PPO 的动机与 TRPO 相同:使用当前拥有的数据对策略采取最大可能的改进步骤,但不至于意外导致性能崩溃。TRPO 尝试使用复杂的二阶方法来解决这个问题,而 PPO 是一系列一阶方法,它使用一些其他技巧来保持新策略接近旧策略。 PPO 方法的实现和计算都要简单得多,并且从经验来看,其性能似乎至少与 TRPO 一样好。
PPO 有两个主要版本:
- PPO-Penalty: 近似求解类似 TRPO 的 KL 约束更新,在目标函数中以惩罚项的形式引入 KL 约束,而不是像 TRPO 一样将其作为硬约束。它会在在训练过程中自动调整惩罚系数,以便适当地缩放。
- PPO-Clip: 在目标函数中没用 KL 散度,也不进行任何约束,而是在目标函数中引入适当的剪切来抑制策略更新的幅度。
其中 PPO-Clip 是最常用的版本。
PPO-Penalty
PPO-Penalty 用拉格朗日乘数法直接将 KL 散度以惩罚项的形式放进了目标函数中,使其变成一个无约束的优化问题,在选定的过程中的不断更新 KL 散度的系数。即:
令 (旧策略所访问的各个状态上,新旧策略的 KL 散度), 的更新规则如下:
- 如果 , 那么
- 如果 , 那么
- 否则
其中 是超参数,用于限制学习策略和之前策略的差距。
PPO-Clip
PPO-Clip 采用以下更新:
其中 是一个超参数,它粗略地表示新策略允许与旧策略相差多远。
将 记为 。TRPO 中的 surrogate advantage 就是 的期望。直观地讲,(1) 式是 的带上下界的版本。通过 我们消除了将 移到区间 之外的激励。通过取剪切和未剪切目标的最小值,我们使得最终目标是未剪切目标的下界(即悲观界限)。
下图展示了 与 的关系: