时序差分 (Temporal Difference, TD) 是强化学习中的一个重要概念,常见于 “TD 算法”、“TD 误差”、“TD 目标” 等名词中。
TD 目标
这里引用《深度强化学习》中的一个例子:
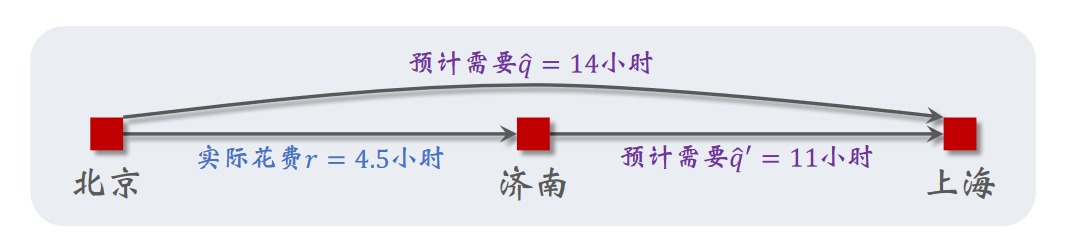
假设模型 (通过某种初始化) 估计从北京到上海一共需要 小时,从济南到上海估计需要 小时。智能体实际上花费了 小时从北京到济南。即使智能体没有继续从济南到上海,这一信息也能用于模型的更新。模型对北京到上海的预计总用时可以被更新为 小时。
这里 被称为 TD 目标 (TD target),它比最初的预测 更加可靠。它被形式化地定义为:
TD 误差和 TD 损失
我们可以使用 对模型做修正。假设模型使用 参数化,最初的估计值记为 ,使用 TD 损失 (TD loss) 作为损失函数:
实际上是 的函数,但是我们不会让它参与梯度计算
计算损失函数的梯度得到
其中 称为 TD 误差 (TD error)。我们可以用 TD 误差来对神经网络进行更新:
这样的学习方式被称为 TD 学习 (TD learning) 或者 TD 算法。
自举与蒙特卡洛
在训练模型时,如果将一个 episode 进行到底,观察所有奖励并进行网络更新 (即在前面的例子中完整地从北京走到上海) ,这种方法被称为蒙特卡洛 (Monte Carlo) 方法,即完整地计算回报 ,用它去近似它的期望 。蒙特卡洛方法的好处是无偏性;坏处是其随机性高,方差大,收敛较慢。
而 TD 方法是自举 (bootstrapping) 方法,即使用模型的估计值来更新自身。TD 方法的好处是随机性只来自 , 方差小,收敛较快;坏处是有偏差,因为模型自身的估计可能有偏差。
多步 TD
上面的 TD 目标只使用一个奖励,这样得到的 是单步 TD 目标。多步 TD 目标 (multi-step TD target) 使用多个奖励,可以视作是单步 TD 目标的推广。
假设 episode 长度为 , 分别写出 时刻的折扣回报:
于是有
等式两边关于 取期望得到
于是得到 m 步 TD 目标 (m-step TD target):
多步 TD 目标介于蒙特卡洛和自举之间,如果 调整得当,可以在方差和偏差之间取得较好的平衡。